Up/Down sampling phase space data using gaussian KDE
Sometimes, phase space data is very large - much larger than it actually needs to be to serve our purposes.
Othertimes, phase data is too small. For example, for good quality Monte Carlo simulations, a lot of independant primary particles are required - but simulating such particles is an expensive task, so you generally do not wish to simulate more particles than are required to represent the space.
This tutorial demonstrate how we can solve these issues using gaussian kernel density estimates.
Before we go any further: a warning! These approaches are fairly heuristic, and there is no guarantee they will be valid for your data. You should undertake a very careful comparison of the input and output data if you intend to utilise this approach.
Example: Downsampling a large phase space
Let’s load in some data:
[1]:
from pathlib import Path
import sys
sys.path.append('../') # not necessary when the library is installed
from ParticlePhaseSpace import DataLoaders
from ParticlePhaseSpace import PhaseSpace
import numpy as np
from matplotlib import pyplot as plt
test_data_loc = Path(r'../tests/test_data/coll_PhaseSpace_xAng_0.00_yAng_0.00_angular_error_0.0.phsp').absolute()
ps_data = DataLoaders.Load_TopasData(test_data_loc)
PS = PhaseSpace(ps_data)
PS = PS('gammas') # take only the gammas for this example
print(f'data has {len(PS)} particles')
data has 308280 particles
This is a pretty dense set of particles, and for the purpose of this tutorial I will argue that I don’t actually need all these particles to represent my phase space properly (this is probably not really the case in actuality).
Of course, we could just downsample this phase space using the get_downsampled_phase_space method; this would generate a new phase space by randomly sampling the current one. However, there is no guarantee that such an approach will preserve the distributions of your input data. A more sophisticated approach is fit some function to the phase space, and then sample from this function to generate new data. This is a challening problem, because we have seven dimensions we care about (we do not
handle time in this approach):
x, y, z, px, py, pz, weight
We cannot assume that any of these quantities are independant: we have to assume correlations exist between all 7. A popular choice for such problems is gaussian kernel density estimates.
Clean input data
In general, the KDE fit appears to be quite sensitive to ‘tails’ in data. Since phase space data is often prone to having long tails in e.g. energy or position, and since we often don’t actually care about those tails anyway, it can be a good idea to manually remove them. Since I know from previous analysis that nearly all data lies between -2<=x,y<=2, I am going to remove the particles outside this range:
[2]:
filter_input_data = True
if filter_input_data:
spatial_cutoff = 3
keep_ind = np.logical_and(np.abs(PS.ps_data['x [mm]'])<spatial_cutoff, np.abs(PS.ps_data['y [mm]'])<spatial_cutoff)
PS, PS_discard = PS.filter_by_boolean_index(keep_ind, split=True)
data where boolean_index=True accounts for 86.0 % of the original data
Note that we use filter_by_boolean_index(split=True) to split this PhaseSpace into two objects. In principle, we could model the PS_discard object with it’s own KDE, but as the name implies: I am just going to discard it!
Now we have cleaned the input a little, we can generate the KDE based phase space:
[3]:
new_PS = PS.resample_via_gaussian_kde(n_new_particles_factor=0.5, interpolate_weights=False)
print(f'original data has {len(PS)} entries, new data has {len(new_PS)} entries')
original data has 265149 entries, new data has 132574 entries
/home/brendan/Documents/python/ParticlePhaseSpace/ParticlePhaseSpace/_ParticlePhaseSpace.py:1487: UserWarning: This method is quite experimental and should be used with extreme caution;always manually compare the new PhaseSpace data to the old PhaseSpace data to ensure it is close enough for your requirements
warnings.warn('This method is quite experimental and should be used with extreme caution;'
Ad-hoc data cleaning steps
The below steps are implemented in an ad hoc way to improve the kde fit. You can turn them off to see what happens when they aren’t implemented! Such ad-hoc steps are hard to implement in a general fashion, so we leave it to individual users to apply these to their own case.
Reflect Pz
First, let’s compare the momentums:
[4]:
PS.plot.momentum_hist_1D()
new_PS.plot.momentum_hist_1D()
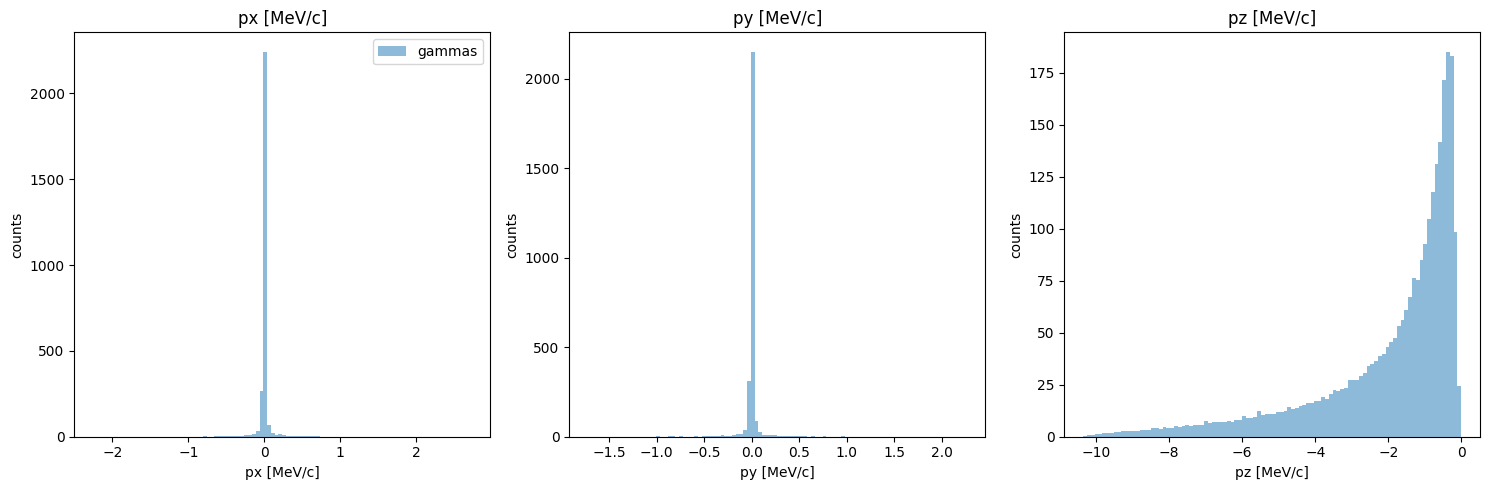
You can see that in the original data, all values of pz are negative, but in the KDE generated data, the momentums are positive. This is a general problem with KDE; to solve it, we have two options:
remove all particles with pz>0 - the issue is that (a) this is a big chunk of our partilces, and (b) doing so would fundamentally change the energy histogram, which - although i haven’t shown this - actually matches quite well.
Reflect the positive values into negative
I am going to take the second approach:
[5]:
reflect_pz =True
if reflect_pz:
new_PS.ps_data['pz [MeV/c]'] = -1* np.abs(new_PS.ps_data['pz [MeV/c]'])
new_PS.reset_phase_space()
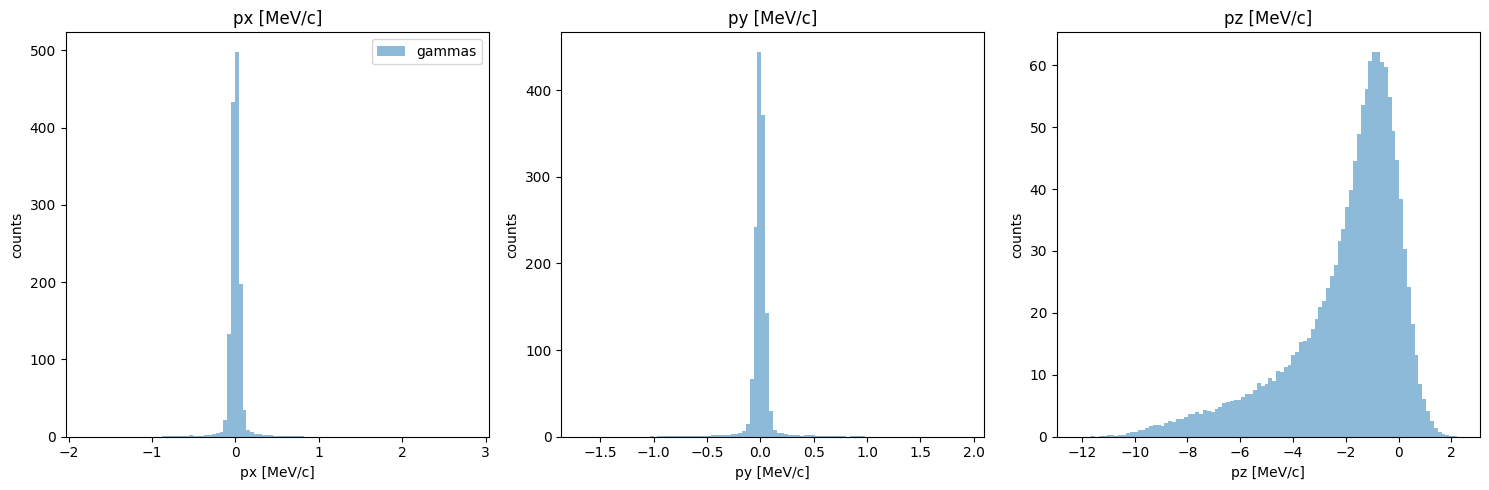
new_PS.plot.momentum_hist_1D()
Ok, momentum looks much closer now! Note that I used the reset_phase_space method, as is recomended whenever we interact directly with the phase space data like this.
Remove high divergence particles
Let’s take a look at the beam divergences:
[6]:
PS.plot.transverse_trace_space_hist_2D()
new_PS.plot.transverse_trace_space_hist_2D()
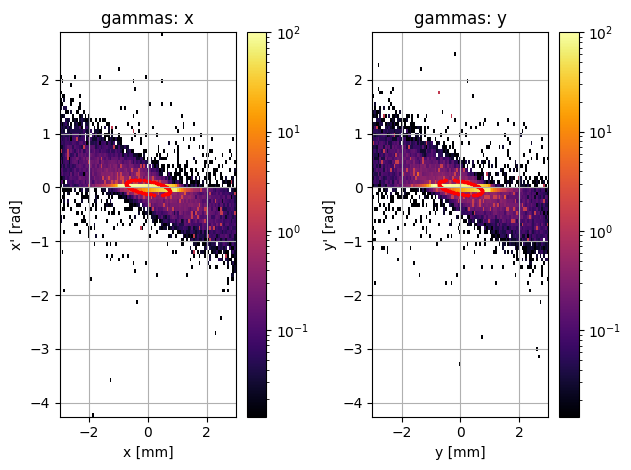
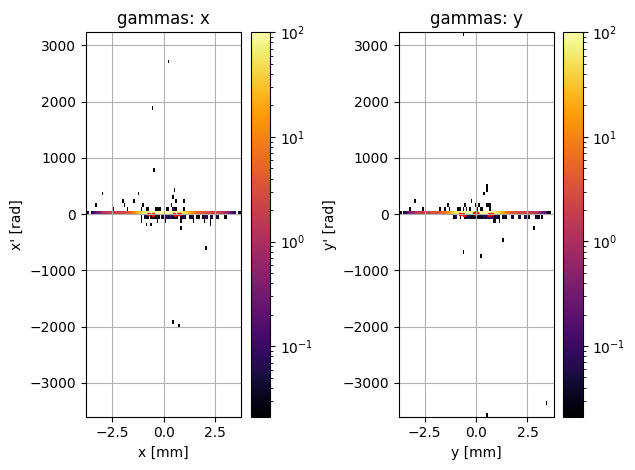
This is a bit of a disaster; these plots look completely different. However, it actually appears that there are only a few outlier particles causing the second plot to look so different. We could just try removing these particles:
[7]:
# remove particles that have higher divergence than the maximum divergence in the original data:
remove_high_divergence_particles=True
if remove_high_divergence_particles:
div_x = np.abs(new_PS.ps_data['px [MeV/c]'] / new_PS.ps_data['pz [MeV/c]'])
div_y = np.abs(new_PS.ps_data['py [MeV/c]'] / new_PS.ps_data['pz [MeV/c]'])
max_div_x = np.max(np.abs(PS.ps_data['px [MeV/c]'] / PS.ps_data['pz [MeV/c]']))
max_div_y = np.max(np.abs(PS.ps_data['py [MeV/c]'] / PS.ps_data['pz [MeV/c]']))
rem_ind = np.logical_or(div_x > max_div_x, div_y > max_div_y)
new_PS.filter_by_boolean_index(np.logical_not(rem_ind), in_place=True)
new_PS.reset_phase_space()
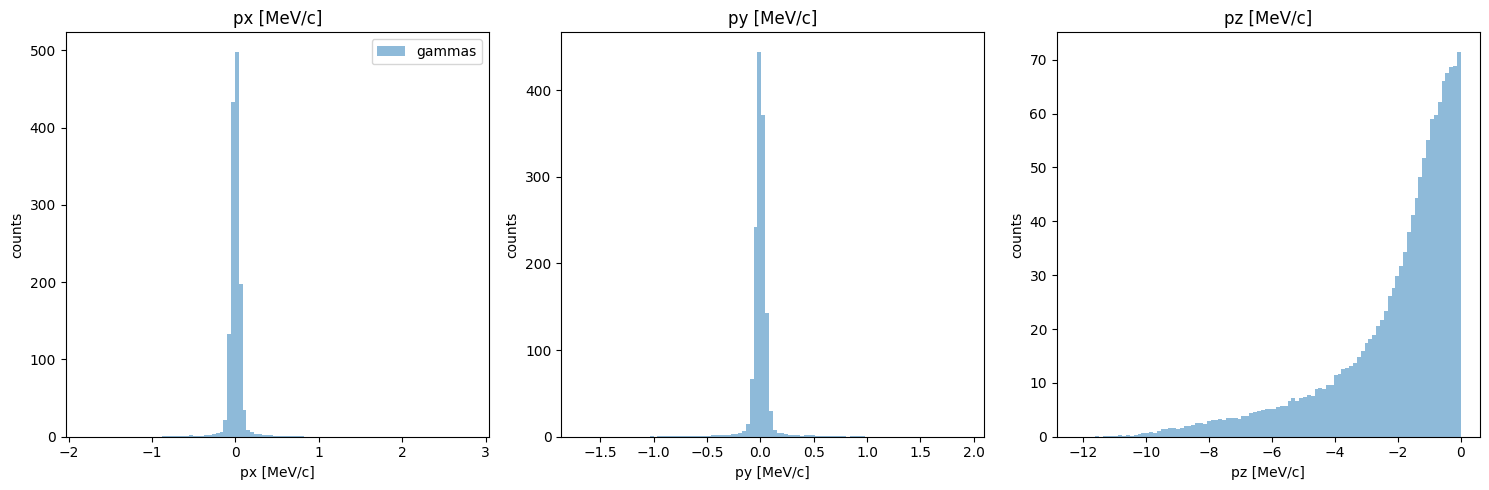
new_PS.plot.transverse_trace_space_hist_2D()
removed 0.8 % of particles
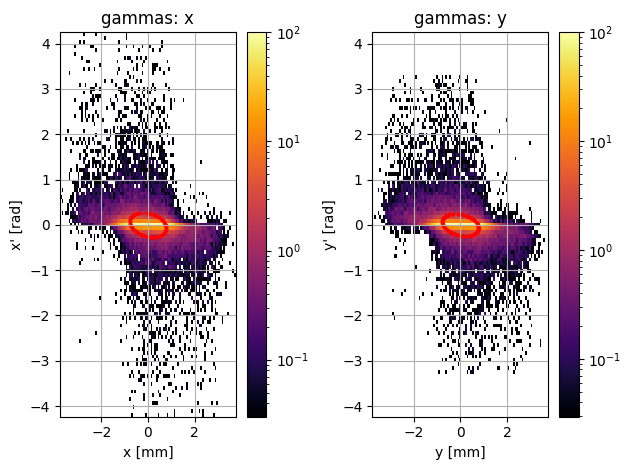
[8]:
PS.print_twiss_parameters()
new_PS.print_twiss_parameters()
===================================================
TWISS PARAMETERS
===================================================
gammas:
x y
epsilon 0.089075 0.089526
alpha 0.568640 0.563796
beta 6.168591 6.133908
gamma 0.214531 0.214849
===================================================
TWISS PARAMETERS
===================================================
gammas:
x y
epsilon 0.199379 0.179031
alpha 0.265812 0.283737
beta 3.047858 3.386484
gamma 0.351282 0.319064
The emittance still doesn’t match perfectly, but it’s not terrible anymore either… by removing just a few outlier particles, we manged to get a phase space which looks much closer to the original!
Now that we have cleaned up the data, let’s compare the original data to the downsampled data:
Compare original to downsampled:
Energy
[9]:
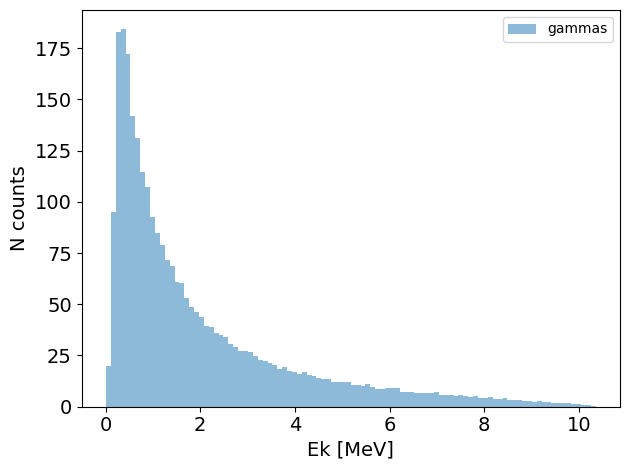
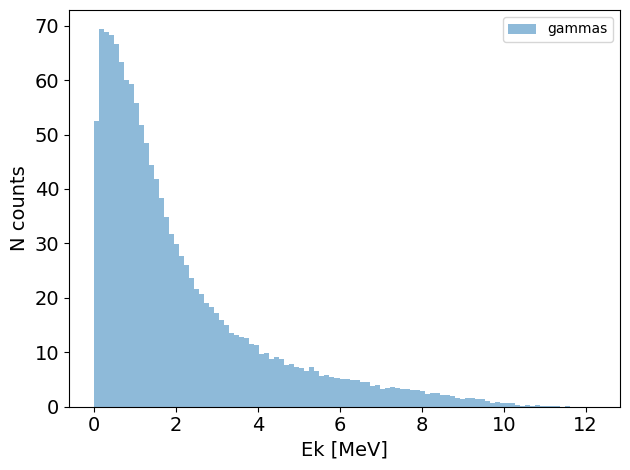
PS.plot.energy_hist_1D()
new_PS.plot.energy_hist_1D()
[10]:
PS.print_energy_stats()
new_PS.print_energy_stats()
===================================================
ENERGY STATS
===================================================
total number of particles in phase space: 265149
number of unique particle species: 1
265149 gammas
mean energy: 2.00 MeV
median energy: 1.23 MeV
Energy spread IQR: 2.18 MeV
min energy 0.01 MeV
max energy 10.35 MeV
===================================================
ENERGY STATS
===================================================
total number of particles in phase space: 131554
number of unique particle species: 1
131554 gammas
mean energy: 2.12 MeV
median energy: 1.42 MeV
Energy spread IQR: 2.23 MeV
min energy 0.00 MeV
max energy 11.71 MeV
Momentum
although we already compared momentum, this may have changed since we filtered out high divergence particles. let’s check:
[11]:
PS.plot.momentum_hist_1D()
new_PS.plot.momentum_hist_1D()
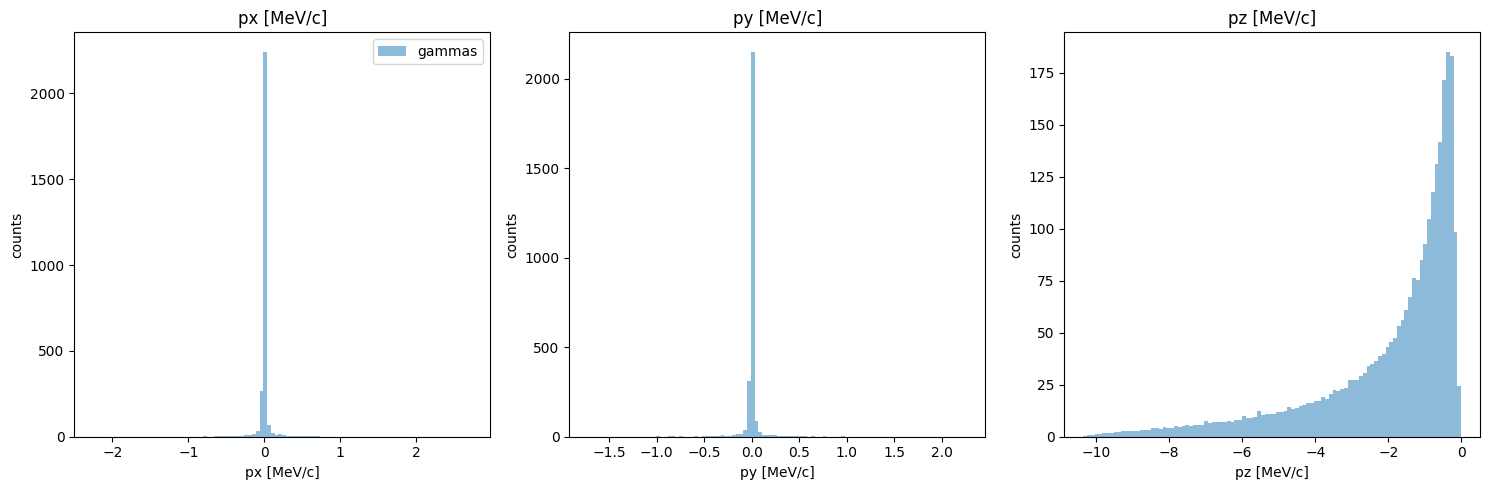
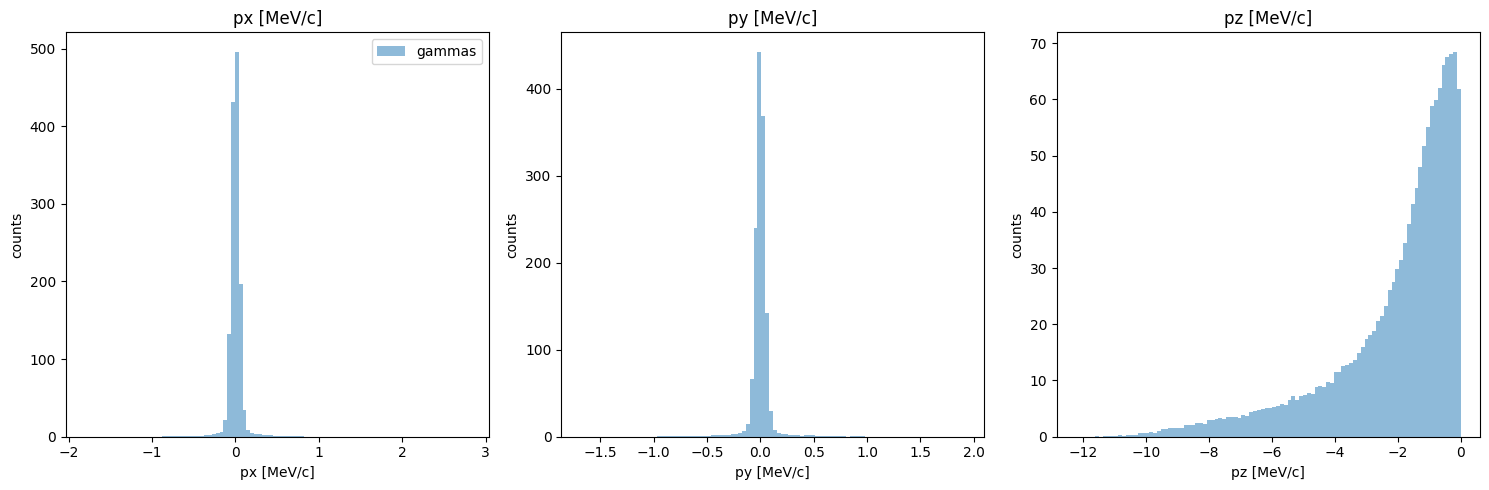
Looking pretty good!
Particle Positions
[12]:
PS.plot.position_hist_1D()
new_PS.plot.position_hist_1D()
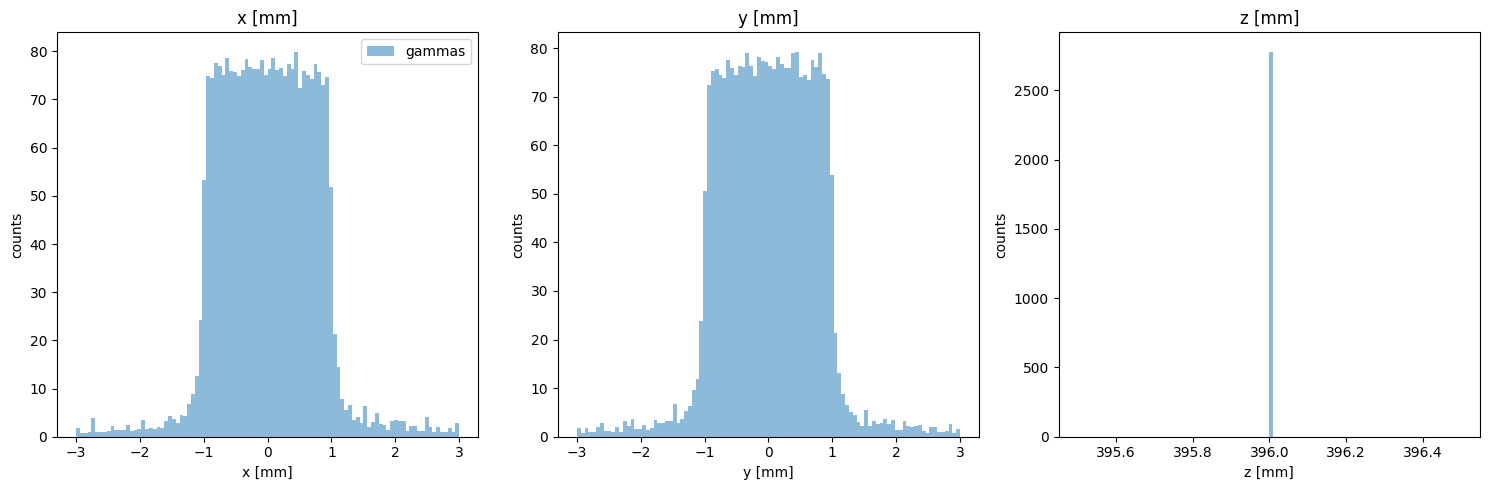
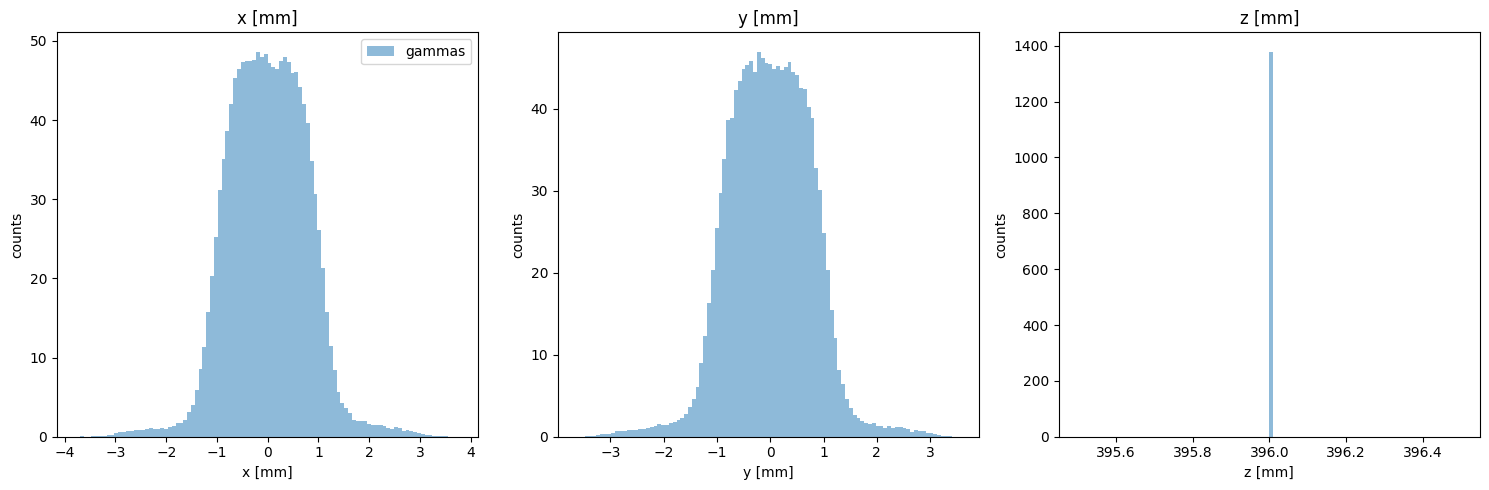
[13]:
PS.plot.particle_positions_hist_2D(xlim=[-5,5], ylim=[-5,5])
new_PS.plot.particle_positions_hist_2D(xlim=[-5,5], ylim=[-5,5])
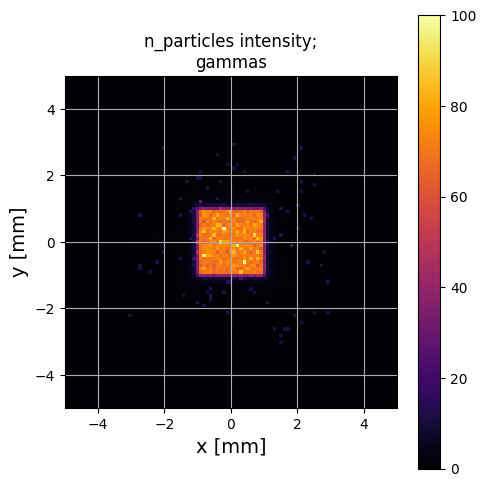
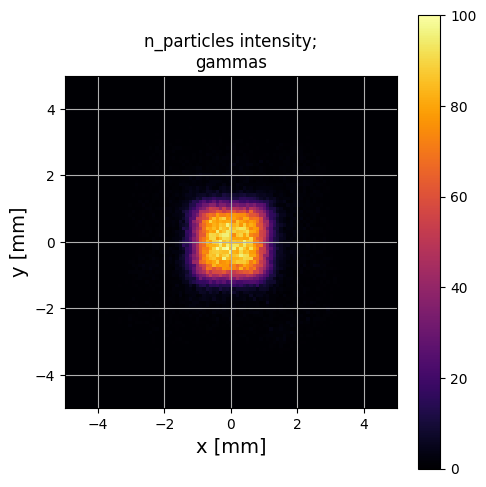
Again, this is a reasonable looking guess - although as an excercise, see what happens if you set filter_input_data=False above! This will cause this estimate to fail quite badly.
As you can see, it is possible using this approach to get a reasonable match to your input data This allows you to both upsample and downsample a phase space. Of course, as I mentioned above:
be careful!
consider what the accuracy requirements are for your specfic application!